Exploiting KeepKey CVE-2021-31616 - Part I
I have recently discovered the serious CVE-2021-31616 vulnerability in the KeepKey hardware wallet.
This is part I of a small article series that describes some of the technical journey of how I got code execution on the device.
Contents
Consulting
I’m a freelance Security Consultant and currently available for new projects. If you are looking for assistance to secure your projects or organization, contact me.
Overview
I highly recommend starting with the technical description of the bug in the original advisory article to get the overview and code context for the following sections.
The vulnerability at the heart of CVE-2021-31616 gives an attacker the opportunity to perform a very controllable out-of-bounds write on the stack of the device via an Ethereum-related protobuf message. The combination of length and data control of the write allows an attacker to aim for three different attack variants:
- Write into protected areas of the memory to intentionally trigger some crash behavior
- Write into other stack variables that lie beyond the target buffer to manipulate data that the KeepKey operates on
- Write into essential pointers on the stack and get direct control over the code execution on the device (depending on countermeasures)
From my personal experience, this situation is somewhat exceptional since the write behavior of bugs is usually much more restricted. This made the bug extra interesting to dig into.
First Attack: Crashing the Device
This is the easiest attack.
On the target ARM Cortex M3 microcontroller, the stack grows from higher memory addresses to lower memory addresses
and the out-of-bounds write through the memcpy() changes memory from the end of the target buffer into higher memory addresses.
Since the memory region of the existing stack frames (= content on the stack) is limited to a few hundred bytes and is located in the “direction” of the out-of-bounds write,
an attacker can trigger a large memcpy() to write over all of them and beyond the last addresses of the stack.
The source contents do not matter since the intention is to trigger the memory protection that is active for the following memory section.
This immediately results in a microcontroller fault.
In practical terms, the attacker has to send a single MessageType_EthereumSignTx protobuf message with a large msg->data_length value and filler content in the msg->data_initial_chunk field.
Upon processing, the KeepKey code will then perform the large write operation through the bug.
For the x86_64 kkemu version of the program and enabled AddressSanitizer (ASAN), the crashing memcpy() operation looks like this:
==22768==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7ffe9af8fe20 at pc 0x0000005273ba bp 0x7ffe9af8fb90 sp 0x7ffe9af8f358
WRITE of size 6431 at 0x7ffe9af8fe20 thread T0
#0 0x5273b9 in __asan_memcpy (keepkey-firmware/build1/bin/kkemu+0x5273b9)
#1 0x57265a in ethereum_extractThorchainData /keepkey-firmware/lib/firmware/ethereum.c
#2 0x5781b1 in ethereum_signing_init /keepkey-firmware/lib/firmware/ethereum.c
#3 0x5d4831 in fsm_msgEthereumSignTx /keepkey-firmware/lib/firmware/fsm_msg_ethereum.h
#4 0x77495b in dispatch /keepkey-firmware/lib/board/messages.c
#5 0x773f86 in usb_rx_helper /keepkey-firmware/lib/board/messages.c
#6 0x774c22 in handle_usb_rx /keepkey-firmware/lib/board/messages.c
#7 0x7867ab in usbPoll /keepkey-firmware/lib/board/udp.c
#8 0x55dd39 in exec() /keepkey-firmware/tools/emulator/main.cpp
#9 0x77aedd in delay_ms_with_callback /keepkey-firmware/lib/board/timer.c
[...]
The expected memory protection unit (MPU) based crash behavior can be confirmed on a physical KeepKey target device with firmware v7.0.3.
By repeatedly sending malicious messages with different msg->data_length values, the crash can be narrowed down to memcpy() lengths of >=941 and happens reliably at exactly that length.
From there on, overwriting larger memory areas simply results in the same crash, as expected. This also tells us that the beginning of swap_data is about 940 bytes away from the
end of the stack (minus some other value and padding).

The impact in this situation is a crash of the device with the error display Memory Fault Detected through the
mmhisr() error handler.
The device needs to be unplugged before working again, but the problematic effects are gone after a restart.
Note that there is a second variant of this crash with similar impact, which will be covered in the next section.
Second Attack: Manipulating Local Stack Variables
The first attack used the stack buffer overflow to crash the device. This is mostly a bit alarming and inconvenient to the user, but has no effects on the integrity or confidentiality and is non-permanent, so this is usually not seen as a big deal by vendors.
An attacker would like to manipulate the actual program to make it do something problematic without also crashing immediately in the process.
One approach to do this is by overwriting other local stack variables in the same function.
In theory, this can work really well since the protective stack canary memory segments that are inserted in the target binary through -fstack-protector-all guard only
the memory region behind the local variables.
Also, the MPU configuration is static by design and always configured to allow arbitrary read & write accesses of this region, so it is also not detecting anything problematic.
As a result, the local stack variables are basically left unprotected against sequential memory overwrites in C.
In the best case for the attacker, the essential variables that the program operates on can be changed on the fly to bypass logical checks and do something dangerous. In practice, this depends a lot on the affected function, target architecture, compiler and specifically used compiler settings.
By debugging the x64_64 program fuzzer variant of the firmware in the problematic ethereum_signing_init() call,
I got a quick generic overview of all local variables that might be relevant in this stack frame:
(gdb) info local swap_data = '\000' <repeats 255 times> swap_data_len = 0 '\000' token = 0x0 data_needs_confirm = true is_approve = false confirm_body_message = [shortened] rlp_length = 5448905
This looks promising at first. There are length fields, confirmation flags and so on. But let’s look a bit closer.
In the mentioned out-of-bounds write situation captured from the first attack variant, the ASAN debug information during the out-of-bounds write looks like this:
Address 0x7ffe9af8fe20 is located in stack of thread T0 at offset 288 in frame
#0 0x574d6f in ethereum_signing_init /keepkey-firmware/lib/firmware/ethereum.c
This frame has 2 object(s):
[32, 288) 'swap_data' (line 698)
[352, 704) 'confirm_body_message' (line 721)
Note that most local variables are already out of the picture and only one variable is still relevant, at least in this modified version of the firmware code.
swap_data can potentially overwrite the memory region where confirm_body_message lives,
which in turn is used to display strings to the user as part of the confirmation dialog for Ethereum transactions.
This might be interesting if we can manipulate the content.
However, after a few minutes of additional analysis, this potential attack also looks very much like a dead end:
confirm_body_messageis explicitly overwritten withmemset()before it is used further down in the function- the branch that uses
confirm_body_messageis mutually exclusive with the one that triggers the bug - triggering the bug also runs into some local error handling, which returns from
ethereum_signing_init()function prematurely
This is getting less and less interesting from an attacker perspective.
The more experienced readers might now say: “but wait, this is your 64-bit x86 fuzzer binary, under a different compiler, with different settings, on a different architecture - this might still be possible on the target firmware.“
And of course, they would be right. Which is why I looked at the binary behavior of the actual 32 bit ARM Cortex-M3 thumb firmware binary that GCC produces,
both for the published firmware.bin as well as the recompiled version with debug symbols (thumbs up to KeepKey for reproducible build environments and open source firmware that helps with security analysis!).
However, the practical situation on the ARM looks even worse.
Since swap_data[256] and confirm_body_message[352] are the only two large buffers in this stack frame
and the GCC is told to do a lot of optimization through -O2,
the compiler uses the fact that confirm_body_message and swap_data variable usage in the normal program are mutually exclusive and
puts them in directly overlapping locations on the stack with identical start addresses.
As a result, they live in the same 352 byte memory region, which is determined by the size of the bigger confirm_body_message variable.
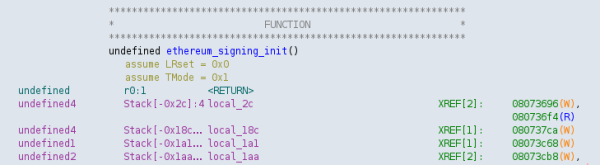
So for this particular vulnerability, overwriting local stack variables is not doing anything useful, and even the compiler knows that.
As with the first attack variant, I’ve tested this against the actual v7.0.3 firmware by sequentially doing larger out-of-bounds memory writes of different sizes and observing the results.
The results are consistent with the described memory placement:
- Writes into
swap_datawith lengths of<= 352do not have any observable side effects or errors. - Writes of size
>= 353cause damage the protective stack canary and trigger the__stack_chk_fail()fault exception.

The resulting impact of the stack canary fault is similar to the one in the first attack,
although it is a bit delayed since it happens once the ethereum_signing_init() function returns and the canary values are checked.
Third Attack: Overwriting Essential Pointers on the Stack
This will be discussed in a following part of the article series. Stay tuned.